| Meetei Mayek and Unicode - Making the Script Immortal - |
|||
By: Tabish Qureshi * |
|||
|
Meitei Mayek Poem :: fHgd_ra samNyada A newcomer wonders what it is, but a computer geek informs him that he doesn't have the right font installed on his computer. And if that it done, these strange words will actually be displayed as Meetei Mayek. Why does this happen? This happens for the following reason. Computers store alphabets as numbers - so, there are certain numbers associated with the Roman letters A, B, C, D etc. The Meetei Mayek font provided by E-Pao maps the Meetei Mayek characters to the same numbers that are used by Roman letters. So, a newcomer who doesn't know that this text is to be viewed with E-Pao's font, sees some gibberish text. The problem is made worse by the fact that there is not just one Meetei Mayek font, there are several, and each has its own mapping of characters. So, a document written in Meetei Mayek using one particular font, will appear as gibberish if seen using some other Meetei Mayek font. So, as things stand now, if a document is typed in Meetei Mayek and sent by email to somebody else, he/she cannot make any sense out of it. So, the gigabytes of stored documents may just appear to be garbage. What one person writes cannot be easily understood by another - this is not a healthy scenario in this era of information technology. The Unicode standard So, is there a solution to this mess? Yes, the answer is Unicode (www.Unicode.org) which is becoming the de-facto standard for storing text in computers. Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language. Once the Unicode standard is adopted, each character will be unique, it will not be replaced by mistake by any other character. A document typed using Unicode standard, will be understandable by everybody, without any ambiguity. Unicode aims to assign a unique number to every characater of every script that exists in the world. Even the scripts which have died out, and are no longer in use, will be included in the Unicode standard. This will make storing of old documents in old scripts possible. The Unicode Standard has been adopted by such industry leaders as Apple, HP, IBM, JustSystem, Microsoft, Oracle, SAP, Sun, Sybase, Unisys and many others. It is supported in all modern computer operating systems like Linux, Windows XP and MacOSX. Most scripts of India, like Devanagari, Tamil, Malayalam, Urdu, Bengali, have already been included in Unicode. Now comes the million dollar question - has Meetei Mayek been included in the Unicode standard? The answer is, not yet. However, the process is under way. The task of preparing a draft for assigning the numbers to Meetei Mayek characters is being coordinated by Michael Everson of Ireland, who is an expert in the writing systems of the world, in consultation with learned persons, and scholars who have done research on the script, both Manipuris and non-Manipuris. The draft proposal for encoding of Meetei Mayek has been finalized and sent to the review board of Script Encoding Initiative (SEI). The SEI, established in the UC Berkeley Department of Linguistics, is a project devoted to the preparation of formal proposals for the encoding of scripts not yet currently supported in Unicode. So, everything is in the pipeline now, and it is only a matter of time before Meetei Mayek will become part of the Unicode standard. One might wonder what difference it will make to a layperson when that happens. Once it happens, the computer you buy, which comes preloaded with Windows or Linux, will already have Unicode compatible fonts, capable of displaying Meetei Mayek characters, installed. You will be easily able to type documents, send emails and chat in Meetei Mayek. And the documents you type and the websites you make in Meetei Mayek, will not appear as gibberish to others - they will appear faithfully as Meetei Mayek. Which form of Meetei Mayek? We all know that the controversy regarding which form of Meetei Mayek should be used, has not died out completely. The two camps have their own reasons to promote 27- or the 35-letter form. One might feel apprehensive about which form of the script Unicode is going to adopt, and whether that will be the right thing to do. Well, the experts who discussed this aspect came to the conclusion that it will be best to include all the characters from all the forms of the script, in Unicode. This will leave room for using any form of Meetei Mayek in the future. For example, if the currently adopted 27-letter form continues in the future, it will be fully Unicode compatible, and yet if there exist some old manuscripts, which were written in the 35-letter form, they can also be typed and stored using the Unicode standard, by using the extra characters encoded in Unicode. Encoding certain characters in Unicode doesn't mean that people have to use them - they can use those characters if they want to.
A wee bit of techincal stuff Now that we have come this far in the discussion, we might as well take a peek at what this coding looks like. The character codes are basically sequences of four hexadecimal numbers, prefixed with a "U+". Hexadecimal numbers are 16 in number (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F). Code elements are grouped logically throughout the range of code points, called the codespace.
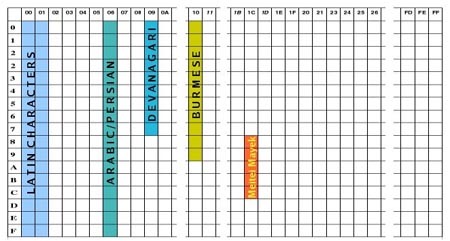
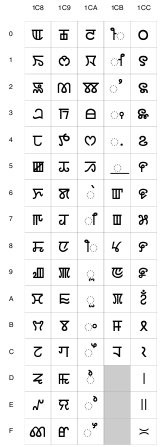
In the codespace chart in figure 1, the fourth number of the code-sequences has been suppressed. For example, the single upper left blue box represents numbers U+0000 to U+000F. One can see blocks of numbers representing various scripts. The numbers U+1C80 to U+1CCF have been reserved for Meetei Mayek. The chart of Meetei Mayek characters proposed for Unicode is displayed in figure 2. It displays three numbers of the sequence as the column number, and the fourth as the row number. Thus, for example, "kok" will be assigned the code U+1C85 and "til" will be assigned the code U+1C94. At this point the reader might have the feeling that this Unicode thing looks too complicated and how will simple users cope with it. The answer to that is that all this coding remains in the background and the user doesn't have to bother with it. For example, for typing "kok" the user wouldn't have to use some complicated method of typing the code U+1C85. The software will take care of how the user types. For example, while using a word-processor, one may just have to select the script "Meetei Mayek" from a menu, and then just press "k" to type a "kok". The word-processor will take care of translating the "k" to the Unicode character code corresponding to "kok". * Tabish Qureshi contributes regularly to e-pao.net . The author can be reached by email at: tabish(AT)jamia-physics.net . This article was webcasted on January 06th, 2007. |
* Comments posted by users in this discussion thread and other parts of this site are opinions of the individuals posting them (whose user ID is displayed alongside) and not the views of e-pao.net. We strongly recommend that users exercise responsibility, sensitivity and caution over language while writing your opinions which will be seen and read by other users. Please read a complete Guideline on using comments on this website.